Ngày nay, nhờ các công cụ tìm kiếm nổi tiếng như Google, Yahoo… mà chúng ta dễ dàng tìm được các thông tin cần tìm trên Internet. Vậy, làm thế nào các công cụ tìm kiếm hiểu được nội dung trên các website? Trong SEO, Web crawler được đánh giá là vô cùng quan trọng trong việc tối ưu hóa website và công cụ tìm kiếm, nâng cao tỷ lệ tiếp cận của kênh online đến với những khách hàng tiềm năng. Vậy, Web crawler là gì? Cách thức hoạt động của Web crawler trên các website như nào? Nội dung bài seminar đã trình bày tổng quan về Web crawler, các thuật toán và cấu trúc dữ liệu phía trong Web crawlers.
Ngày 02/10/2023, Khoa Công nghệ thông tin đã tổ chức buổi seminar khoa học với chủ đề: “Tìm hiểu về trình thu thập thông tin Web crawler” do ThS. Hoàng Thị Hà – Bộ môn Công nghệ phần mềm trình bày.
Buổi seminar có sự tham gia của thành viên nhóm nghiên cứu mạnh “Ứng dụng CNTT trong nông nghiệp” cùng một số giảng viên, cán bộ của khoa CNTT.
    |
 |
| ThS. Hoàng Thị Hà trình bày báo cáo |
Web crawlers là chương trình máy tính, được gọi là robot đi theo các link trên các website để thu thập các thông tin trên www và lưu vào CSDL. Web crawler chính là một “con bot” của công cụ tìm kiếm, có thể thu thập và lập chỉ mục nội dung cho tất cả các website có sẵn. Dựa vào những thông tin từ Web crawler, bất cứ truy vấn nào của người dùng cũng được công cụ tìm kiếm đáp ứng nhanh chóng và kịp thời. Những thông tin phù hợp sẽ được trích xuất ra theo dạng danh sách và kèm với đường link gốc để khách hàng dễ dàng truy cập. Quá trình này thường được gọi là web crawler hoặc crawling.
Công việc chính của crawl gồm: Thu thập dữ liệu từ một trang web bất kỳ; Phân tích mã nguồn HTML nhằm mục đích đọc dữ liệu; Đánh giá, xếp hạng và lưu trữ lại trong cơ sở dữ liệu. Web crawlers còn có các tên gọi khác như: Crawler, Spider, Robot, Web agent.
Về nguyên tắc, trình thu thập dữ liệu giống như một thủ thư. Nó tìm kiếm thông tin trên toàn bộ trang Web, đánh giá và phân loại các danh mục để bất kỳ ai ghé thăm đều có thể dễ dàng và nhanh chóng tìm thấy được thông tin họ cần. Web Crawler sẽ xác định những trang nào cần thu thập thông tin, thứ tự thu thập thông tin và tần suất thu thập thông tin để cập nhật. Quá trình thu thập thông tin cơ bản của crawler qua 3 bước chính sau: 1) Bắt đầu với 1 số URLs đã biết; 2) Quét thông tin từ các URL đã biết (Theo các hyperlink, trích xuất URLs tìm thấy từ cá trang đã biết, thêm các URL mới được phát hiện vào hàng đợi của frontier); 3) Truy cập mỗi URL trên frontier (queue) và lặp lại các bước trên.
|
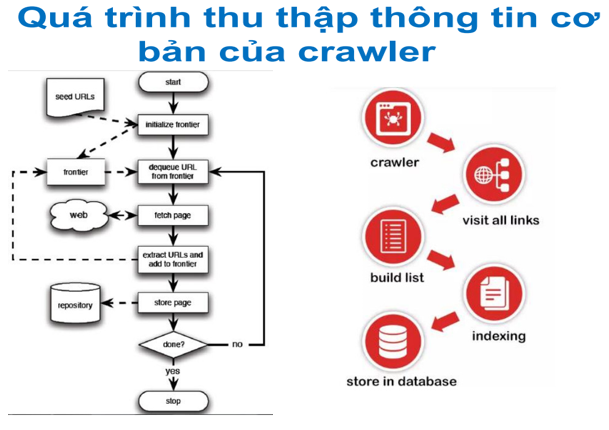 |
| Quy trình thu thập thông tin cơ bản của Crawler |
Các trang web đều được cập nhật và thay đổi thường xuyên, nên điều quan trọng chính là phải xác định được tần suất các công cụ tìm kiếm sẽ thu thập được thông tin. Trình thu thập dữ liệu của công cụ tìm kiếm sử dụng một số thuật toán để quyết định các yếu tố như tần suất tại một trang hiện có nên được thu thập lại thông tin và số lượng trang trên website sẽ được lập chỉ mục. Các thuật toán Crawler cơ bản được sử dụng gồm: 1) Breadth-First Crawlers; 2) Preferential Crawlers.
Trong bài báo cáo, ThS. Hoàng Thị Hà đã đưa ra nhiều ví dụ thực tế về các thuật toán Crawler, về phân tích code HTLM,… Tác giả đã đưa ra các yếu tố chính ảnh hướng đến việc crawl và index của Google, gồm: Tuổi đời domain; Traffic; Tốc độ tải trang; Backlinks; XML Sitemap; Nội dung: update, trùng lặp; Chủ động thông báo cho công cụ tìm kiếm; URL thân thiện với SEO; Meta Tags; Internal Link.
|
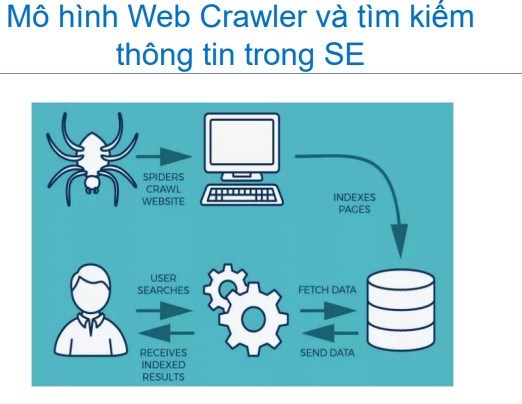 |
| Mô hình Web Crawler và tìm kiếm thông tin trong SEO |
Phần cuối báo cáo, tác giả đã tổng hợp lại các vai trò quan trọng của Web Crawler trong SEO, gồm: 1) Web Crawler sẽ tải xuống các trang web để công cụ tìm kiếm xử lý, lập chỉ mục các trang web này để người dùng tìm kiếm hiệu quả hơn. 2) Người dùng có thể truy xuất bất kỳ thông tin nào trên một hoặc nhiều trang khi cần. Nếu dữ liệu từ trang web không được web crawler thu thập, nó sẽ không thể được (index), trang web không được hiển thị trong kết quả tìm kiếm. (Nội dung chi tiết của bài seminar xem thêm tại đây)
Sau phần trình bày của ThS. Hoàng Thị Hà, thành viên tham dự buổi seminar có nhiều thảo luận xoay quanh chủ đề. Nội dung bài seminar có tính khoa học và ứng dụng cao trong thời đại Công nghệ số hiện nay. Buổi seminar là cơ hội trao đổi học thuật, cập nhật, cung cấp thêm nhiều kiến thức mới về các vấn đề thuộc lĩnh vực công nghệ thông tin. Kết quả thảo luận của buổi seminar làm cơ sở để định hướng, xác định chiến lược khoa học công nghệ của khoa Công nghệ thông tin trong thời gian tới.
Khoa Công nghệ thông tin